.
分类作为数据挖掘领域中一项非常重要的任务,它的目的是学会一个分类函数或分类模型(或者叫做分类器)。
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类(binary classification)的广义线性分类器(generalized linear classifier)。

该网址可更清晰理解(需要翻墙)https://www.youtube.com/watch?v=3liCbRZPrZA
二元分类,又称“二向分类”。在包含两类事项的比较研究中,按两个标志所作的分类。
如在研究学生的智力与性别的关系时,按智力与性别两个标志分类,即为二元分类。

SVM使用铰链损失函数(hinge loss)计算经验风险(empirical
risk)并在求解系统中加入了正则化项以优化结构风险(structural risk),是一个具有稀疏性和稳健性的分类器 [2]
。SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一。

支持向量机:
支持向量机其决策边界是对学习样本求解的 最大边距超平面 (maximum-margin hyperplane)。也就是它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。
支持向量:
H为分类线,H1,H2分别为过各类中分类线最近的样本且平行于分类线的直线,H1,H2上的点为支持向量。
支持向量 机 的机指的是算法。
最优超平面:
如果训练数据可以无误差的被划分,并且每一类数据超平面距离最近的向量与超平面之间的距离最大,则这个平面为最优超平面。
线性SVM:
先看下线性可分的二分类问题。
上图中的(a)是已有的数据,红色和蓝色分别代表两个不同的类别。数据显然是线性可分的,但是将两类数据点分开的直线显然不止一条。上图的(b)和(c)分别给出了B、C两种不同的分类方案,其中黑色实线为分界线,术语称为“决策面”。每个决策面对应了一个线性分类器。
虽然从分类结果上看,分类器A和分类器B的效果是相同的。但是他们的性能是有差距的,看下图:

在"决策面"不变的情况下,我又添加了一个红点。可以看到,分类器B依然能很好的分类结果,而分类器C则出现了分类错误。显然分类器B的"决策面"放置的位置优于分类器C的"决策面"放置的位置,SVM算法也是这么认为的,它的依据就是分类器B的分类间隔比分类器C的分类间隔大。
这里涉及到第一个SVM独有的概念"分类间隔"。在保证决策面方向不变且不会出现错分样本的情况下移动决策面,会在原来的决策面两侧找到两个极限位置(越过该位置就会产生错分现象),如虚线所示。
虚线的位置由决策面的方向和距离原决策面最近的几个样本的位置决定。而这两条平行虚线正中间的分界线就是在保持当前决策面方向不变的前提下的最优决策面。
两条虚线之间的垂直距离就是这个最优决策面对应的分类间隔。显然每一个可能把数据集正确分开的方向都有一个最优决策面(有些方向无论如何移动决策面的位置也不可能将两类样本完全分开),而不同方向的最优决策面的分类间隔通常是不同的,那个具有“最大间隔”的决策面就是SVM要寻找的最优解。
而这个真正的最优解对应的两侧虚线所穿过的样本点,就是SVM中的支持样本点,称为"支持向量"。
1、数学建模
求解这个"决策面"的过程,就是最优化。一个最优化问题通常有两个基本的因素:
- 1)目标函数,也就是你希望什么东西的什么指标达到最好;
- 2)优化对象,你期望通过改变哪些因素来使你的目标函数达到最优。在线性SVM算法中,目标函数显然就是那个"分类间隔",而优化对象则是决策面。所以要对SVM问题进行数学建模,首先要对上述两个对象("分类间隔"和"决策面")进行数学描述。按照一般的思维习惯,我们先描述决策面。
数学建模的时候,先在二维空间建模,然后再推广到多维。
(1)"决策面"方程
我们都知道二维空间下一条直线的方式如下所示:

现在我们做个小小的改变,让原来的x轴变成x1,y轴变成x2
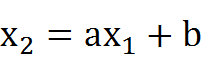
移项得:
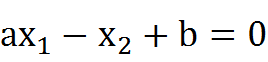
将公式向量化得:
进一步向量化,用w列向量和x列向量和标量γ进一步向量化:
其中,向量w和x分别为:

这里w1=a,w2=-1。我们都知道,最初的那个直线方程a和b的几何意义,a表示直线的斜率,b表示截距,a决定了直线与x轴正方向的夹角,b决定了直线与y轴交点位置。那么向量化后的直线的w和r的几何意义是什么呢?
现在假设:

可得:

在坐标轴上画出直线和向量w:

蓝色的线代表向量w,红色的线代表直线y。我们可以看到向量w和直线的关系为垂直关系。这说明了向量w也控制这直线的方向,只不过是与这个直线的方向是垂直的。标量γ的作用也没有变,依然决定了直线的截距。此时,我们称w为直线的法向量。
二维空间的直线方程已经推导完成,将其推广到n维空间,就变成了超平面方程。(一个超平面,在二维空间的例子就是一个直线)但是它的公式没变,依然是:
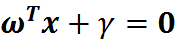
不同之处在于:
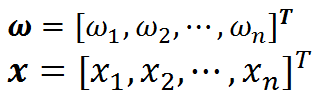
我们已经顺利推导出了"决策面"方程,它就是我们的超平面方程,之后,我们统称其为超平面方程。
(2)"分类间隔"方程
现在,我们依然对于一个二维平面的简单例子进行推导。

我们已经知道间隔的大小实际上就是支持向量对应的样本点到决策面的距离的二倍。那么图中的距离d我们怎么求?我们高中都学过,点到直线的距离距离公式如下:

公式中的直线方程为Ax0+By0+C=0,点P的坐标为(x0,y0)。
现在,将直线方程扩展到多维,求得我们现在的超平面方程,对公式进行如下变形:

这个d就是"分类间隔"。其中||w||表示w的二范数,求所有元素的平方和,然后再开方。比如对于二维平面:

那么,

我们目的是为了找出一个分类效果好的超平面作为分类器。分类器的好坏的评定依据是分类间隔W=2d的大小,即分类间隔w越大,我们认为这个超平面的分类效果越好。此时,求解超平面的问题就变成了求解分类间隔W最大化的为题。W的最大化也就是d最大化的。

点到平面的距离:

分离超平面方程:

SVM适用于(非神经网络)线性分类,非线性分类,线性回归,相比逻辑回归,决策树等模型。